HGPT: Enterprise RAG Knowledge Base
An enterprise AI search engine that allows users to securely query 10,000+ internal documents in real-time, built with Llama 3 and a custom Retrieval-Augmented Generation (RAG) pipeline.
Rationale
Why HGPT? Data privacy and vendor lock-in. Enterprise data cannot always be sent to OpenAI's APIs. By building a custom pipeline using local models via Ollama and ChromaDB, we guarantee zero data leakage. Furthermore, managed services charge heavily per token. A custom hybrid search strategy using local Cross-Encoder re-ranking achieves comparable 50% improved accuracy without the compounding API costs at scale.
The Hardest Challenge: Tuning the chunking strategy. I implemented a parent-child hierarchy, meaning we search through small chunks for millimeter precision, but retrieve the larger surrounding document context for the LLM. This made the generation far more coherent.
Tech Stack
Core Engineering Challenge
The Bottleneck: Relying solely on vector embeddings (ChromaDB) resulted in poor recall for specific keyword queries.
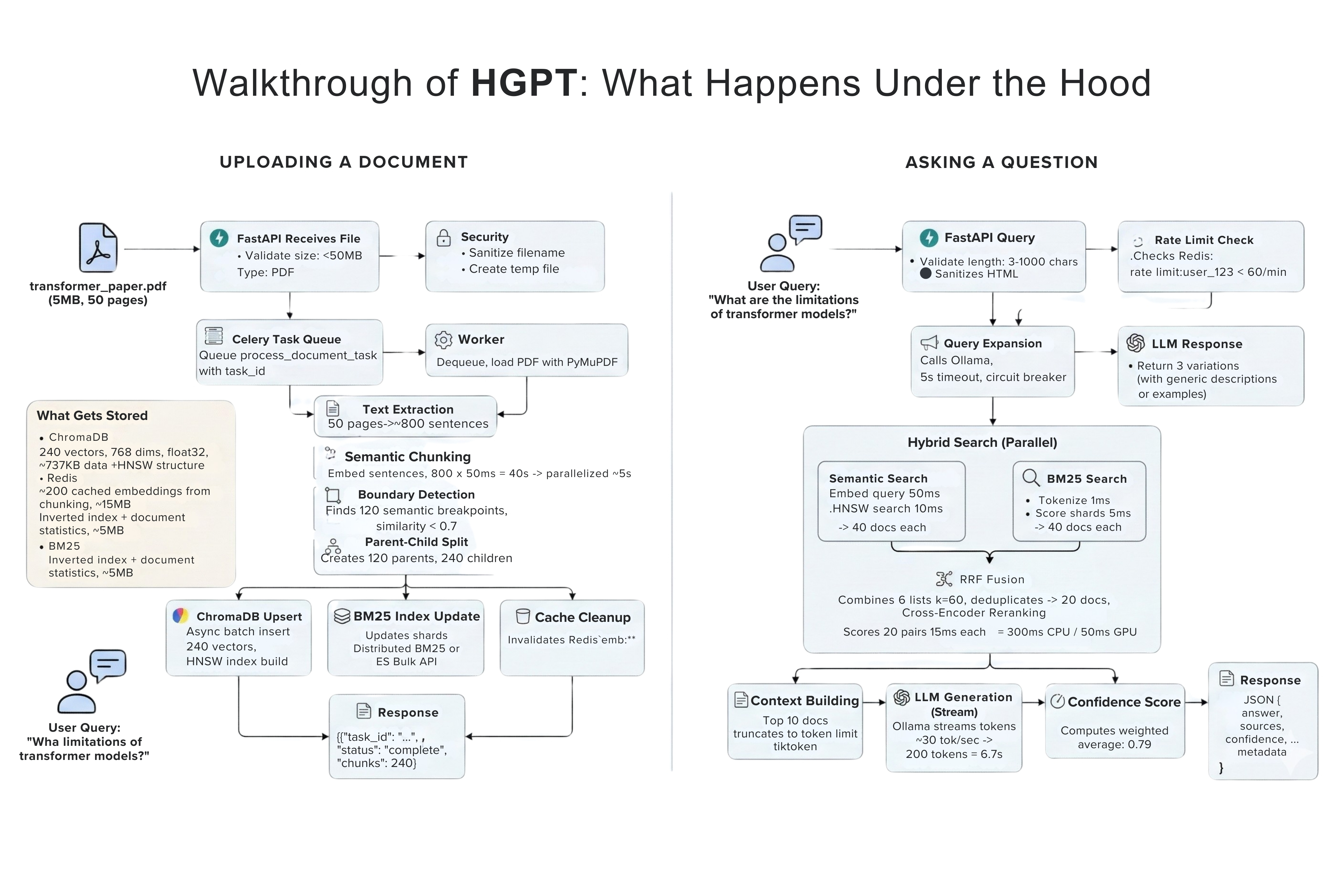
The Solution: I implemented a hybrid search pattern. Queries run in parallel against ChromaDB (semantic) and BM25 (lexical), fusing the results via Reciprocal Rank Fusion (RRF).
The Trade-off: To prevent garbage context from reaching the LLM, I added a cross-encoder to rerank the results. Because cross-encoders are computationally expensive, I strictly bound the reranking step to the top 20 documents, trading a ~300ms latency penalty for a massive spike in accuracy.
Integrated Celery for asynchronous document ingestion so the main event loop never blocks, and wired up Prometheus/Grafana for full observability.
Key Highlights
- ▹Implemented a hybrid search strategy using ChromaDB, BM25 for semantic vector retrieval, and Reciprocal Rank Fusion.
- ▹Cross-Encoder re-ranking to maximize context relevance, improving accuracy by 50% over standard keyword search.
- ▹Enabled high-performance ingestion pipeline using FastAPI and Celery workers to asynchronously process and chunk large datasets into embedded vectors with Chain-of-Thought reasoning without blocking the UI.
Architecture Details
The Enterprise RAG Knowledge Base is built around a decoupled architecture designed for high-throughput ingestion and low-latency retrieval.
1. Data Ingestion Pipeline (Asynchronous)
- FastAPI acts as the ingestion gateway.
- Large PDF and txt documents are pushed to a Celery background worker so the UI doesn't freeze.
- Celery workers parse them, chunk them using contextual splitters, and run DSPy / Llama 3 to extract metadata and perform initial Chain-of-Thought (CoT) reasoning.
2. Hybrid Retrieval Engine
- During a query, both a sparse representation (BM25) and dense representation (embedding) are calculated.
- Reciprocal Rank Fusion (RRF) combines these disparate scoring domains to ensure we get exactly accurate results—not just 'kind of' related ones.
- A Cross-Encoder re-ranks the top K results to guarantee maximum semantic relevance.
3. Observability & Caching
- To make this production-ready, Redis was added to cache repeated queries, driving response times down.
- Prometheus and Jaeger are configured for observability, enabling exact bottleneck tracing if the inference pipeline slows.
Interactive System Design
FastAPI Rate-Limited Gateway
Engineering Insight
Validates incoming queries rapidly while checking strict sliding-window rate limits via Redis to prevent unauth LLM abuse.
Technical Walkthrough
Engineering Insights
The Reality of RAG
"An LLM-as-a-judge that agrees with itself is not an eval."
Level 1: LLM API Wrapper
No tools, no architecture, no memory. Just passing prompts.
Level 2: Basic RAG
Vector Retrieval. 90% of the industry is stuck here.
Level 3: Functional Agent
Systems that can think, act, use external tools, and answer.
Level 4: Multi-Agent Reasoning
Autonomous research, context management, and deep monitoring.
Getting from Level 2 to Level 4 requires serious engineering. When I built the HGPT RAG system, implementing hybrid retrieval (BM25 + Semantic), Reciprocal Rank Fusion, and cross-encoder reranking proved one thing: moving past basic vector search is expensive. The better your recall and reasoning, the higher your compute cost. This 'memory tax' is the biggest bottleneck in local AI architecture right now.